Numpy.Float64' Object Cannot Be Interpreted As An Index
The 'Numpy.Float64' object cannot be interpreted as an index error is a common issue encountered by developers when working with the NumPy library in Python. NumPy is a powerful library for numerical computing that provides efficient and high-performance multidimensional array operations. However, when using NumPy arrays and attempting to use a 'float64' object as an index, this error arises.
Author:Elisa MuellerReviewer:James PierceMay 26, 20236.8K Shares142.5K Views
The 'Numpy.Float64' object cannot be interpreted as an indexerror is a common issue encountered by developers when working with the NumPy library in Python.
NumPy is a powerful library for numerical computing that provides efficient and high-performance multidimensional array operations. However, when using NumPy arrays and attempting to use a 'float64' object as an index, this error arises.
What Is NumPy?
NumPy, short for Numerical Python, is a fundamental library in Python for scientific computing. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
With NumPy, developers can perform various mathematical and logical operations on arrays with ease, making it a valuable tool for tasks such as data analysis, machine learning, and scientific research. Its performance optimizations, built-in functions, and extensive mathematical capabilities make it a preferred choice among Python programmers.
Understanding The Error: 'Numpy.Float64' Object Cannot Be Interpreted As An Index
When working with NumPy arrays, it is crucial to understand that array indices must be integers or slices. However, in certain situations, the 'Numpy.Float64' object cannot be interpreted as an index error arises when attempting to use a floating-point number as an index. This error message indicates that the provided index is not of the expected integer type, specifically 'float64'.
Common Scenarios Leading To The Error
These are some common scenarios leading to the error:
Accidental Use Of Floating-Point Values As Indices
One common scenario where this error occurs is when developers accidentally use floating-point values as indices. For example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
index = 2.5
print(arr[index])
In this example, the index variable is assigned a floating-point value of 2.5. When attempting to access the element at index 2.5, the 'Numpy.Float64' object cannot be interpreted as an index error is raised.
Incorrect Conversion Of Data Types
Another scenario leading to this error is the incorrect conversion of data types. NumPy arrays have a fixed data type, and attempting to use an index of a different data type can result in this error. Consider the following example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
index = np.float64(2)
print(arr[index])
Here, the index is explicitly converted to a 'float64' object using the np.float64() function. However, this conversion is unnecessary and leads to the error. The index should be a regular integer for successful indexing.
Mathematical Calculations Resulting In Floating-Point Indices
Sometimes, the error can occur due to mathematical calculations that result in floating-point indices. Consider the following example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
index = 5 / 2
print(arr[index])
In this case, the index value is the result of dividing 5 by 2, which is 2.5. As we have seen before, using a floating-point index will trigger the error.
Strategies To Resolve The Error
Now that we have explored the common scenarios leading to the 'Numpy.Float64' object cannot be interpreted as an index error, let's discuss strategies to resolve it.
Ensure Indices Are Integer Values
To avoid this error, it is essential to ensure that the indices used for accessing NumPy arrays are integer values. You can achieve this by explicitly converting the indices to integers using the int() function. For example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
index = int(2.5)
print(arr[index])
In this modified code snippet, the floating-point index value of 2.5 is explicitly converted to an integer using the int() function. Now, the index is a valid integer, and the error is resolved.
Check For Incorrect Data Type Conversions
If you encounter the error due to incorrect data type conversions, ensure that you are using the correct data type for indexing. Avoid unnecessary conversions to floating-point types like 'float64' and stick to integers. Here's an example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
index = 2 # No need for conversion
print(arr[index])
In this updated code snippet, the index is assigned directly to an integer value without any unnecessary conversions. This approach eliminates the error and ensures correct indexing.
Review Mathematical Calculations And Indexing Logic
If the error arises from mathematical calculations resulting in floating-point indices, it is crucial to review your code's indexing logic. Consider whether using floating-point indices aligns with your intended behavior. If not, revise your calculations or adjust the logic accordingly. Here's an example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
index = int(5 / 2) # Divide and convert to integer
print(arr[index])
In this modified code snippet, the mathematical calculation resulting in a floating-point index is fixed by dividing 5 by 2 and then converting the result to an integer. The error is resolved, and the correct element is accessed from the array.
The Difference Between Indexing And Slicing In NumPy
In NumPy, indexing and slicing are essential techniques for accessing and manipulating data within arrays. While they serve similar purposes, there are distinct differences between indexing and slicing operations.
Indexing refers to accessing individual elements or groups of elements from an array. In NumPy, indexing is done using square brackets []. We can use integer indices or boolean masks to extract specific elements from an array. For example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(arr[0]) # Output: 1
print(arr[[0, 2, 4]]) # Output: [1, 3, 5]
In the above code snippet, arr[0] accesses the element at index 0, while arr[[0, 2, 4]] retrieves elements at indices 0, 2, and 4.
On the other hand, slicing involves extracting a portion of an array by specifying a range of indices. The slicing syntax in NumPy follows the start:stop:step pattern. For instance:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(arr[1:4]) # Output: [2, 3, 4]
print(arr[::2]) # Output: [1, 3, 5]
In the above example, arr[1:4] retrieves elements from index 1 to index 3 (exclusive), while arr[::2] extracts elements at even indices.
Comparing NumPy Indexing With Python Lists
NumPy arrays and Python lists are both widely used for storing and manipulating data. While they share some similarities, there are significant differences between NumPy indexing and indexing in Python lists.
In NumPy, indexing provides a more powerful and concise way to access and manipulate array elements compared to traditional Python lists. NumPy indexing allows for accessing multiple elements simultaneously, using boolean masks for filtering, and applying mathematical operations on entire arrays. For example:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(arr[[0, 2, 4]]) # Output: [1, 3, 5]
print(arr[arr > 2]) # Output: [3, 4, 5]
print(arr * 2) # Output: [2, 4, 6, 8, 10]
In the above code snippet, NumPy indexing allows us to extract specific elements, filter elements based on a condition, and perform element-wise multiplication with a scalar value.
In contrast, indexing in Python lists is more limited. It primarily involves accessing individual elements using integer indices. While lists also support slicing, they lack the advanced indexing capabilities provided by NumPy. Here's an example:
my_list = [1, 2, 3, 4, 5]
print(my_list[0]) # Output: 1
print(my_list[1:4]) # Output: [2, 3, 4]
In this code snippet, we can see that Python lists offer basic indexing and slicing functionality, but they don't support the advanced indexing features available in NumPy.

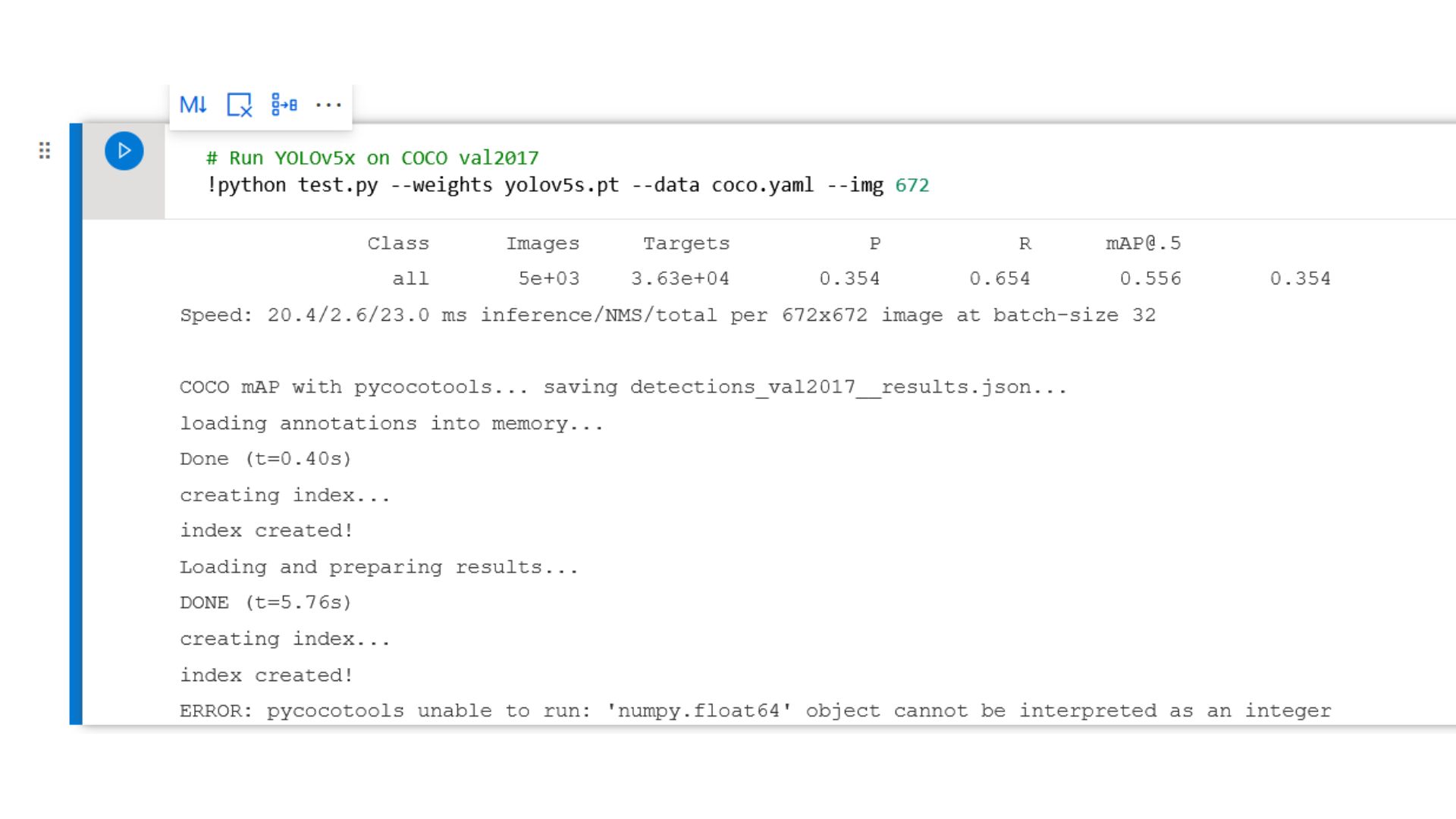
TypeError: 'numpy.float64' object cannot be interpreted as an integer / tensorflow object detection
Performance Considerations For NumPy Array Indexing
When working with NumPy array indexing, there are some key performance considerations to keep in mind:
- Memory Access Patterns- Accessing array elements sequentially or with regular strides improves performance, while random or irregular access patterns can introduce cache misses and decrease efficiency. Try to structure your indexing operations to take advantage of sequential or regular memory access.
- View vs. Copy- NumPy arrays support views, which provide efficient memory usage and faster operations by avoiding data duplication. Be aware of whether an operation creates a view or a copy to optimize memory consumption and performance. You can use the .base attribute of the array to check this.
- Boolean Indexing Performance- Boolean indexing creates a temporary boolean array for the selection mask, which can consume significant memory for large arrays. If memory usage is a concern, consider using alternative approaches like bitwise operators or the np.nonzero() function.
People Also Ask
How Do I Create An Empty NumPy Array?
Use the np.empty() function to create an empty NumPy array.
How Can I Find The Maximum Value In A NumPy Array?
Use the np.max() function to find the maximum value in a NumPy array.
How Do I Concatenate Two NumPy Arrays?
Use the np.concatenate() function to concatenate two NumPy arrays.
How Do I Generate Random Numbers In NumPy?
Use the np.random module to generate random numbers and arrays in NumPy.
Conclusion
The 'Numpy.Float64' object cannot be interpreted as an index error that occurs when attempting to use a floating-point value as an index in NumPy arrays. This error commonly arises due to accidental usage of floating-point values, incorrect data type conversions, or mathematical calculations resulting in floating-point indices.
To resolve this error, it is important to ensure that indices are integer values, avoid unnecessary data type conversions, and review the logic of your indexing operations. By following these strategies, you can overcome this error and work with NumPy arrays more effectively.
Jump to
What Is NumPy?
Understanding The Error: 'Numpy.Float64' Object Cannot Be Interpreted As An Index
Common Scenarios Leading To The Error
Strategies To Resolve The Error
The Difference Between Indexing And Slicing In NumPy
Comparing NumPy Indexing With Python Lists
Performance Considerations For NumPy Array Indexing
People Also Ask
Conclusion

Elisa Mueller
Author

James Pierce
Reviewer
Latest Articles
Popular Articles